
活性化関数と聞いて何を思い浮かぶでしょうか?深層学習を勉強されている方であればいくつか思い浮かぶものがあるかも?と思いますが、実際に論文でどの活性化関数が多く使われているのか?といったことについて paperwithcode(https://paperswithcode.com/methods/category/activation-functions) に記載の論文での使用数を用いてランキング化して紹介します!
各活性化関数についての詳しい説明は別の記事でしようと思っているので、この記事ではランキングを眺めるような形で見てもらえたらと思います!
活性化関数まとめ
先に今回の記事で登場する活性化関数を図にまとめてみると、下の図のようになります!
このように見てみると、それぞれ似ているところや特徴的なところが見えてきますね!
ベスト10
1位 ReLU
論文使用数:5667
いわずとしれた活性化関数の代表
f(x) = max(0,x)
2位 Sigmoid Activation
論文使用数:3913
f(x) = \frac{1}{1+\mathrm{e}^{x}}
3位 Tanh Activation
論文使用数:3700
正値を返すことが多い活性化関数に対して、この関数では正値と負値を同等に扱っている
f(x) = \frac{\mathrm{e}^{x}-\mathrm{e}^{-x}}{\mathrm{e}^{x}+\mathrm{e}^{-x}}
4位 GELU
論文使用数:2692
Gaussian Error Linear Units の略。\Phi (x)は標準ガウス累積分布関数。
GPT-3 や BERT, Transformersなどに
GELU(x) = x \Phi (x)
5位 Leaky ReLU
論文使用数:519
ReLUの拡張版で、入力値が正の部分は全く同じ。
負の時、ReLUだと0を返すがLeaky ReLUだと微小な勾配で表される。
a = 0.01 とすることが多い
f(x) = max(ax,x)
6位 Swish
論文使用数:144
シンプルな定義式になっていて、入力値×シグモイド関数である。\betaは学習可能なパラメータ
f(x) = x \cdot sigmoid(\beta x)
7位 Softplus
論文使用数:137
入力値にかかわらず、正の値で返す活性化関数
f(x) = log(1+exp(x))
8位 Mish
論文使用数:121
新しい活性化関数。2019年に提案
f(x) = x \cdot tanh(softplus(x))
9位 GLU
論文使用数:86
Gated Linear Unit の略
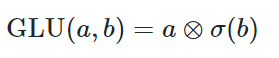
10位 PReLU
論文使用数:58
Leaky ReLUと同じで、ReLUの拡張版。
Leaky ReLUでは入力値が負のときに、どれだけ重みをつけて返すのか?については任意の値となっていたが、これをパラメータとして捉えて動的に決めていく活性化関数

コメント