
英語で書かれている PDF を翻訳して読みたいとき、みなさんはどうしてますか?一文ずつコピーして DeepLなどの翻訳機にかけるのは手間がかかる。しかし、そのままコピーすると文の途中で改行が入ってしまって形が崩れてしまう... などの問題が出てきますよね~
そこで、PDF の文章を読み込んで、DeepLで翻訳させることができたら手間もかからず最高ですよね!!
この記事では、実際に PDF の文章を読み込む + DeepLに翻訳 という過程をプログラム付きで紹介していきます!!
PDF の 文章を読み込む
PDF に変換することで、文字化けが起こりにくく異なる端末間でも共有がしやすいというメリットがあります。
しかし、これまでは逆に文章を読み取ってデータの活用がしにくいということが課題になっていました。
そこで最近では、PDFは表示するだけではなく、読み取り や 編集ができるようなライブラリが出てきています。このブログでは以前に、「PyMuPDF」や 「Borb」をまとめていきましたが、今回は「PyMuPDF」を用いて実装を行います!


この記事では実装に必要な最低限のことを取り上げるので、PyMuPDF の使い方や説明が欲しい方は 上の記事を見てもらえたらと思います!
PyMuPDF インストール
pip install でインストールすることができます!
pip install pymupdfPDF の 読み込み
PDF を 読み込むときに必要となるのは、下の5行です。
というより、たった5行で読み込めてしまうのは驚きですよね!簡単です!!
設定が必要な部分は、2行目の 翻訳したい PDF の パスを設定するだけで、あとは PDFを1ページずつ読み込んでいって、get_textにより文章を読み込みます。
import fitz
pdf_file_path = 'book.pdf'
with fitz.open(pdf_file_path) as pdf_in:
for page in pdf_in:
page1 = page.get_text()
pdf_file_path : 翻訳したい PDF の パス
+α) 読み込むページの指定
上のコードの3行目を下のように変更することで読み込むページも指定することができます!
with fitz.open(pdf_file_path) as pdf_in(2,5): この例だと、2ページ 以上 5ページ未満を読み込む → 2,3,4ページを読み込む
DeepL で翻訳
ここまででは PyMuPDF を用いて、PDF内の文章を読み込んできました。そこでここからは読み込んだ文章を 翻訳していきます!
DeepLでは大きく分けて2つの使用方法があります。
① アプリケーションを使用 : ドラック & ドロップの GUI で 3件/ 月 まで翻訳可能 (1件 最大10MB)
② DeepL API を使用 : 50万字 / 月 まで翻訳可能 (Free Plan)
DeepLに直接 PDFを読み込ませても①の方法で翻訳はできますが、月に3つしかできない...
それでは十分に翻訳できないですよね。ということで、APIを使って②の方法で実装していきます!!
DeepL API の詳細 + 登録は下記リンクから (API を使うためには Free Plan で十分ですが Sign up が必要です)

DeepL API (python)
翻訳を活用するコードは 次のように書いていきます!
import requests
page1 = page.get_text()
data = {
'auth_key': '[yourAuthKey]',
'text': page1.replace('-\n','').replace('\n',''),
'target_lang': 'JA'
}
response = requests.post('https://api-free.deepl.com/v2/translate', data=data)
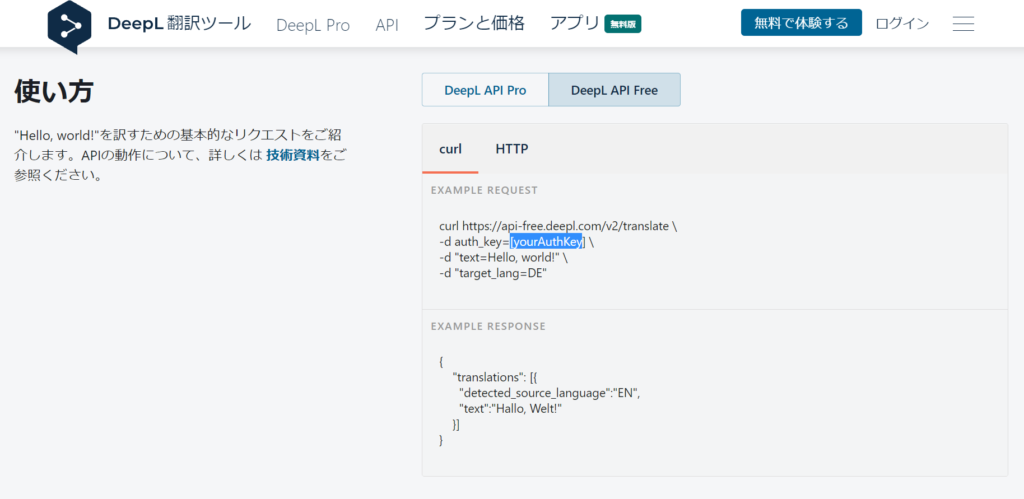
d = json.loads(response.text)① auth_key : API キー
(ログイン後に https://www.deepl.com/pro-api?cta=header-pro-api/ にアクセスすると、下の画面の[yourAuthKey] が変わるのでそれを入力します)
② text : 翻訳したい文章
PyMuPDF で取得した文章データ "page1" を元にしますが、改行文字が入ってしまうので削除を行っています
③ target_lang : 翻訳先の言語
日本語に変換したいので JA を選択
翻訳した結果は Markdown でまとめる!!
ここまでで翻訳することはできましたが、ただ翻訳しただけでこれだけでは確認がしづらいです。そこで翻訳した文章を 取り出し、Markdown 形式に変形していきます!
エンジニアによく使われている Markdown を変換先にしたという理由もありますが、Markdown形式とすることで今回はmdファイルを出力していますが、 一工夫を加えることで Notionなどの Markdown が使えるツールへの 出力も可能になるからです!
このままでも十分使えると思いますが、アレンジを加えてもっと便利にすることもできますよ!!
追加するコードとしては、以下の通りです。 ### で ページごとに H3タグで区切って翻訳内容をまとめていきます!
# for文の中に追加
_text = f"""### Page{page_num}\n{d['translations'][0]['text']}\n"""
text = text + _text
page_num += 1
output_file_path = "output.md"
with open(output_file_path, 'w',encoding='utf-8') as file:
file.write(text)
プログラム 全文
import fitz
import requests
import json
pdf_file_path = 'book.pdf'
output_file_path = "output.md"
page_num = 1
with fitz.open(pdf_file_path) as pdf_in:
text = ""
for page in pdf_in:
page1 = page.get_text()
data = {
'auth_key': '[yourAuthKey]',
'text': page1.replace('-\n','').replace('\n',''),
'target_lang': 'JA'
}
response = requests.post('https://api-free.deepl.com/v2/translate', data=data)
d = json.loads(response.text)
_text = f"""### Page{page_num}\n{d['translations'][0]['text']}\n"""
text = text + _text
page_num += 1
with open(output_file_path, 'w',encoding='utf-8') as file:
file.write(text)

コメント